6 minutes
產品數據分析|快速理解 A/B Testing ,提升產品決策品質
最近,我在 Hahow上一堂以商業應用為核心,結合產品策略與數據分析的課程 — 《產品數據分析 — 打造網路產品的決策引擎》,學習商業應用上的脈絡與框架,作業以 Case Study 的方式為主,利用所學的分析方法、產品策略、思考架構,回答產品個案的相關問題。
學習建立數據指標體系、擬定產品策略後,在日常工作上,指標會浮動、變化,為了理解指標變動的因果關係,許多團隊都會利用 A/B Testing 來實驗、驗證,這個方法也已經非常廣泛的應用在軟體開發、迭代的過程。
0. 簡介
我根據 Hahow 的課程內容和 Udacity 上的熱門課程《A/B Testing by Google》整理成文章,並以 Udacity Final Project 為主要討論。
A/B Testing
A/B Testing 的概念其實不難,就是提供使用者兩個版本的產品,經由統計假說檢定,來判斷實驗結果是否會如我們的預期,特定變數會產生顯著差異,例如:增加註冊步驟,能夠降低註冊率。
雖然實際執行上有很多的 Tips 和嚴謹的細節控制,但這篇主要以方法論為主,我將流程簡化成以下幾個步驟,分享 A/B Testing 的基本概念、流程,不著墨在統計與理論上,並製作了 Cheat Sheet,讓大家在面試前能夠快速複習!
1. 商業洞察,好的問題決定實驗方向
身爲商業分析師、或依數據做決策的職位,我們必須同時了解業務需求和資料應用,左手用 Python 處理資料,右手撰寫投影簡報。日常工作幾乎都和資料為伍,整理資料、了解資料外,也需要利用商業邏輯來詮釋資料。從資料發現 Insight 後、產品改動決策前,我們可以依賴 A/B Testing 的結果,作為決策參考之一。
舉例而言,Udacity 認為一週上線課程時間太短的學生容易取消課程,因此他們想在學生點選 start free trial 按鈕後、註冊前,多一個步驟,詢問學生預期的每週學習時間,如果學生回答的時數低於五小時,則建議他不要註冊,直接免費觀看課程影片(不會拿到證書),希望能減少早期取消率。
足夠的領域知識,加上好的觀察和現象,能夠幫助我們提出對的問題,也能帶領產品往好的方向發展。
2. 實驗設計,讓你實驗不做白工
實驗設計是 A/B Testing 最重要的環節,會直接影響實驗成敗和決策品質,選定指標尤其重要!
選定指標
根據我們的商業假說:詢問學生預期的每週學習時間可以降低學生註冊率。接著需要選擇合適的指標來進行實驗,指標分為兩種:
實驗指標(Evaluation):真正衡量此次實驗所造成的影響,實驗指標的選定和商業假說和目標有關,一次實驗只能有一個實驗指標,確保實驗邏輯能夠驗證因果關係。
例如:註冊率
控制指標(Invariant):用來做驗證實驗,不應該在實驗組和控制組之間發生變化,否則代表實驗不正確。
例如:進入網頁的 cookie 數量、點選 start free trial 的 cookie 數量、點擊率
指標的選定必須經過嚴格的考量,我們可以藉由一些測試來判斷指標是否堪用。
指標測試
選定的指標需要具備靈敏度與穩定度,舉例來說,我們會想了解解析度和影片串流延遲的影響,希望指標能夠根據不同解析度產生變化,但不希望指標在不同影片間隨意變動!
靈敏度(Sensitivity):實驗變數能有效看出差異,對同群人來說,解析度改變會影響串流延遲。 穩健性(Robustness):控制指標不會對指標造成隨意變動,對不同群人來說,類似的影片不會影響串流延遲。
我們可以藉由 A/A Testing 來衡量靈敏度和穩健性,確保實驗在改動前,指標在不同群體間具有代表性。
A/A Testing:和 A/B Testing 的差異在於,平分流量到控制組、實驗組,判斷相同體驗之間的是否沒有差異。
分組與抽樣
實驗通常只會針對特定的一小群人進行,因此需要找出符合我們假說的目標群體,選擇恰當的分組方式和抽樣方法。
分組方式:常見的分組方式可以依據人口統計資料 Demographic、市場類型(包含國家、市場規模)、平台、用戶行為進行分群。 抽樣方法:樣本單位(劃分的最小粒度)可以是 Cookie、User ID、Device ID,依照不同的需求,使用不同的單位,進行抽樣。
好的分組和抽樣方式可以確保隨機性與獨立性,避免實驗產生偏剖。此實驗以 Cookie 為主,因為註冊前無法得知使用者的 User ID!
統計檢定
建立商業假說後,我們在這個步驟將其轉換成統計假說,設立虛無假設(H0) 與對立假設(H1)。
虛無假設(Null Hypothesis):這個改動不會有效地減少課程註冊率。
對立假設(Alternative Hypothesis):這個改動會有效地減少課程註冊率。
並且準備下列要素,以此計算實驗所需樣本數量。
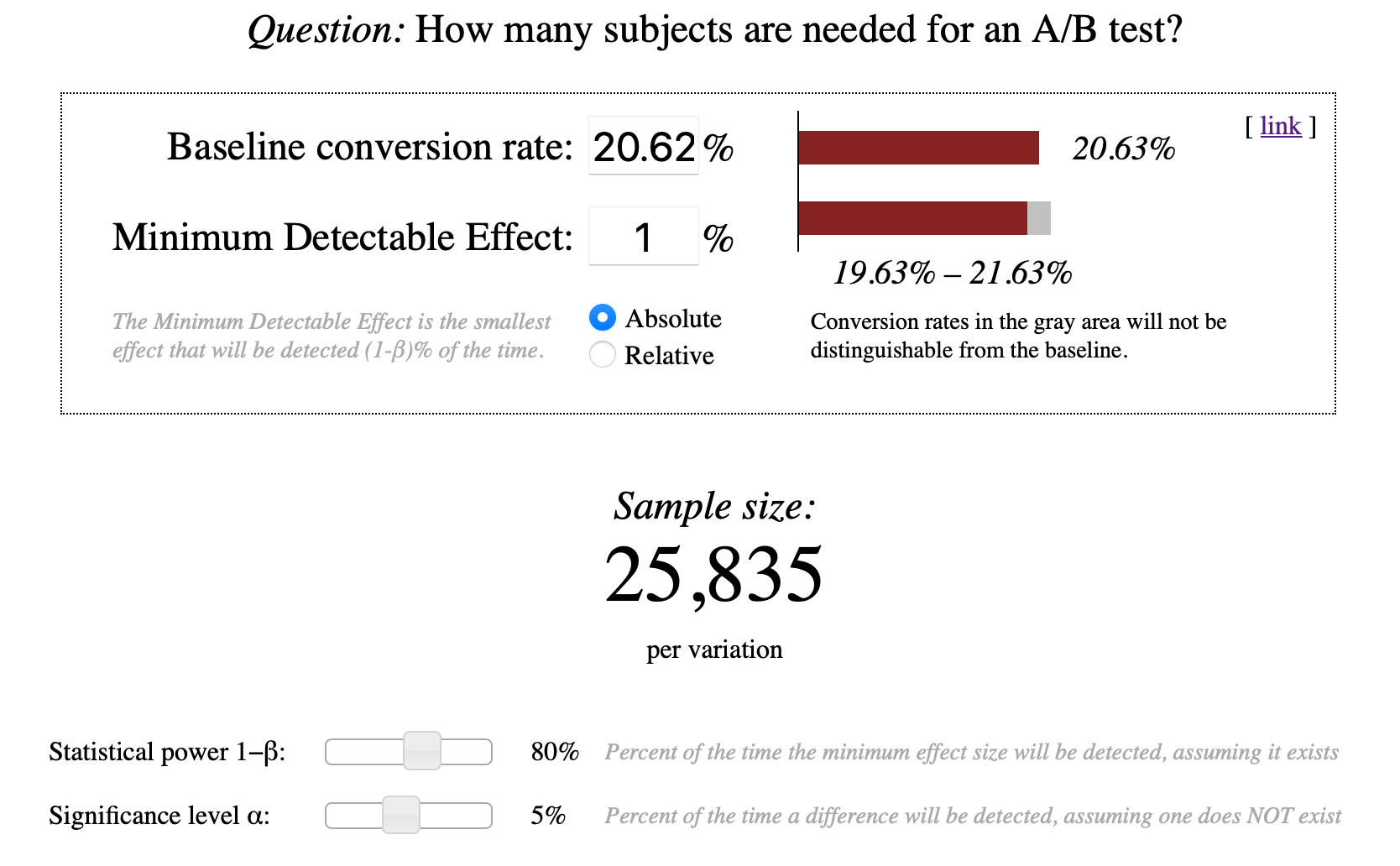
- 原始轉換率(Baseline Conversion Rate):20.625%
- 最小改善程度(Minimum Detectable Effect, MDE):1%
- 顯著水準(Significant Level, α):5%
- 檢定力(Power, 1-β):80%
樣本數量
可以利用這個工具將上述數值輸入,即可取得樣本數量為 25,835 註冊人數/每組,而實驗分為控制組和實驗組,因此總共需要 51,670 註冊人數。
 Sizing。圖/Ryan
Sizing。圖/Ryan
3. 實驗進行
計算所需要的樣本數後,要將流量平均分配在一定的時間單位內,實驗時長通常為一至兩週,且在實驗期間內,要考慮週期性或是其他因素,例如,國定假日可能導致流量較高,避免實驗期間環境和實驗設計時的考量有衝突,影響準確性。
實驗進行中,應進行監測,以免技術錯誤或其他技術問題,造成偏誤,同時,當達到實驗所需的樣本數後,應該隨即結束實驗,切勿因為結果尚未達到顯著性,而繼續實驗,因以實驗的設計為主,實驗時間拉長,可能造成顯著性陷阱(增加樣本數能夠同時降低 α、β)。
4. 結果分析
實驗結束後,切勿沒有計算統計檢定,只看最終數字變化(控制組的註冊數量少於實驗組),就妄下決定!很有可能實驗組只是「隨機」出現你想看到的結果,因此我們首先要做完整性測試(Sanity Check),確保我們的實驗設置和進行都是正確的,然後再來分析結果並給出結論與建議。
Sanity Check
控制組和實驗組會在點選 “start free trial”,才會面對不同的頁面,因此在此之前的數據應該保持一致,控制指標在兩組間不隨意變動。未通過 Sanity Check 代表實驗不正確,不需要繼續分析後續結果,應回頭檢視實驗步驟,找出錯誤環節。
 Sanity Check Table。圖/Ryan
Sanity Check Table。圖/Ryan
實驗顯著性
計算實驗變數在兩組間是否有顯著差異,顯著水準需要小於 α、檢定力大於(1-β),同時考慮絕對值與分佈,信賴區間越窄越好。
增加詢問學生預期的每週學習時間後(實驗組),在學生註冊課程的場景中,實驗組相較控制組降低了 2.1% 的完成註冊率,達到統計上的顯著性!
 Significant Level。圖/Ryan
Significant Level。圖/Ryan
5. 後續行動
實驗是為了幫助我們做決定,但是實驗的顯著性跟是否要將改動上線其實是兩件事,畢竟仍有許多更動造成的結果是不可量化的。
上述實驗雖然降低了學生的註冊率,但不一定可以有效減少早期取消率,或是有其他成本的考量、也可能產生使用者反感、忽略辛普森悖論等等的,需要做後續更多的實驗、或是釐清使用者行為等,才能決定是否要上線。
上述提供的資料和實驗僅是為了說明,實際上 Udacity Final Project 有更多的問題、實驗的設置,如果大家有興趣的話,非常建議可以把這堂線上課程上完,如果內容有誤,也請大家留言幫忙勘誤!